From Voice to Workplan: Maleen Kidiwela’s Agentic Productivity Loop
Last month, UW Postdoc Maleen Kidiwela and I have been experimenting with a workflow he has been quietly building for his own research productivity. The stack was novel to me: Obsidian, Claude, and a tool he developed called VaultNotes. In practice, it behaves more like a personal research operating system than a conventional note-taking setup.
The part that caught my attention was not just the tooling. It was the continuity of the research activity. Maleen and I brainstormed ideas for a hyper-parameter study for seismology into Claude voice, those notes are stored and retrieved against a broader note corpus, reorganized into a workplan, and then visualized to reveal relationships between projects, questions, and prior thinking. In some cases, updated workplans can even become scripts that run in the background.
This feels like an early example of something larger: work productivity moving directly from speech to science and back again.
A Small, Real Moment
One way to understand this system is to start with an ordinary academic problem: too many parallel threads, too many different tasks and roles, too many partial notes, and too much context switching.
Instead of treating note capture, planning, and execution as separate tasks, Maleen has been experimenting with collapsing them into a single loop.
“A small example from a recent week. I was looking at the HYS14 clock-drift correction in our ChronFix pipeline and noticed a faint staircase pattern in the corrected cross-correlations that should not have been there. On the walk home I dictated a loose set of thoughts into Claude voice about where it might be coming from, mostly suspecting the picker quantum interacting with how I was smoothing the hourly Δt. By the time I sat down at my desk those fragments were already in the vault next to my original V1 method writeup and the Chronos diagnostic notes from a few days earlier. A short prompt against VaultNotes pulled that prior context together and reorganized everything into a clear plan: switch from the global smoothing in V1 to per-segment robust Δt smoothing, add a boundary-snap fix in the resampling step, and write a V2 method document that supersedes V1 with the diagnostic plots to back it up. What would normally have taken a week of rereading old notes and rederiving my own reasoning compressed into roughly a day.” - Maleen Kidiwela
That concrete example matters because it keeps the discussion grounded in practice rather than abstraction. The interesting question is not whether these tools are impressive, it is wether we can unlock productivity, accountability, tracability, and creativity.
Role Decomposition
What I find useful here is that Maleen’s system touches several academic roles at once.
As scientists, we still have to decide what is novel but plausible, what matters, and what evidence is needed. That human judgment cannot disappear.
As project managers, we have to sequence research tasks, track data-method-software dependencies, and keep multiple research project moving.
As an infrastructure builder, Maleen is designing the architecture that links notes, retrieval, planning, and execution, a model that our other group members are adopting.
This is where the value of agentic tooling becomes clearer. It supports the coordination layer around scientific reasoning and multi-tasking.
“The project-manager role is where VaultNotes earns its keep. Sequencing tasks across data ingestion, QC, database design, and the intelligence layer used to live in my head and in scattered Obsidian dailies; now retrieval surfaces the right thread at the right moment, and plans inherit prior dependencies instead of being rewritten from scratch. The infrastructure-builder role is partially supported because the tool itself is the infrastructure, which keeps it honest. The scientist role remains stubbornly manual, and I think it should. Deciding whether a noise pattern in an OBS station is instrumental or geological, or whether a database schema actually respects how oceanographers and seismologists query the same record, is not something I want a retrieval layer to summarize away.” - Maleen Kidiwela
The Mechanism
What makes this workflow interesting is that it is a context architecture.
A simplified version of the loop looks like this:
- Speech capture through Claude voice.
- Storage of those notes inside an Obsidian vault.
- Retrieval over existing notes through VaultNotes with RAG.
- Reorganization of raw notes into a structured plan.
- Visualization of links across projects and notes.
- Promotion of updated workplans into scripts or jobs that can run in the background.
This is the part of the story that signals a real shift. We are no longer talking only about writing assistance or summarization. We are talking about a workflow in which language interfaces begin to connect thought capture, memory retrieval, planning, and potentially action.
VaultNotes sits on top of an ordinary Obsidian vault. It selectively publishes chosen folders to a static GitHub Pages site, and a daily launchd job keeps the published copy in step with the local notes. The retrieval layer is section-aware: a GitHub Action parses Markdown headings, splits and folds chunks, and embeds them with Gemini. At query time the browser does hybrid retrieval locally over BM25, lexical matching, and embeddings, with same-section neighbor expansion so a question lands inside its surrounding context rather than a stray sentence. Date phrasing like “yesterday” or “April 4th” is normalized to the indexed YYYY-MM-DD so daily notes stay addressable. Plans turn into action because the vault is just files: once a workplan is written into a note, the same launchd schedule that syncs the site can also drive scripts that read those notes, and a Cloudflare Worker brokers chat queries when I want to ask the corpus a question.
Where It Helps
The most immediate benefit of a system like this is continuity.
Academic work is fragmented by design. We move from meetings to coding to teaching to reviewing to writing, often several times in the same day. A voice-to-plan loop helps preserve state across those interruptions.
Instead of leaving ideas trapped in transient audio, half-formed notes, or scattered task lists, the system keeps pushing them toward structure.
That changes the shape of productivity in a subtle but important way. The value is not just speed, it is reduced loss and time-waste, transparency, accountability, and rigor.
“The biggest change has been the time I no longer spend recovering context. Working across an offshore observatory, multiple data streams, and a database design effort means every Monday used to start with a quiet hour of rereading my own notes just to remember where I left off. That hour is gone. The vault remembers, retrieval surfaces what is relevant, and I start the week already inside the problem.” - Maleen Kidiwela
Failure Modes and Guardrails
Any workflow built around retrieval and language models can fail in familiar ways, especially when built without proper eval. Retrieval can pull in notes that are semantically related but contextually wrong. Generated plans can sound coherent while encoding poor priorities. Visualizations can imply meaningful structure where there is only superficial linkage. Scripts generated too quickly can automate mistakes.
These are not side issues. They are the core reason human judgment remains non-negotiable and where future evaluation of these systems will become critical.
“My guardrails are deliberately boring. Nothing the model produces becomes a runnable job without me reading it end to end, and scripts that touch raw observatory data or write back to the database are gated by an explicit dry-run on a small segment first. Retrieved notes are always shown to me before a plan is accepted, because the failure mode I worry about is a confident plan built on a semantically related but contextually wrong fragment, for example a parameter choice from a different deployment that happens to use similar vocabulary. Decisions that touch scientific judgment, including station selection, QC thresholds, and schema choices for the multimodal database, stay fully manual. The system is allowed to organize, retrieve, and propose; it is not allowed to decide.” - Maleen Kidiwela
This is, to me, the difference between a credible agentic workflow and a fragile demo.
The Broader Pattern
What Maleen is building suggests that context engineering is becoming a practical research skill.
Not in the abstract sense of “prompting well,” but in the more durable sense of designing systems that preserve memory, structure work, and move reliably from reflection on research practice to action.
That may matter especially for early-career researchers. In a world of increasing cognitive fragmentation (deep science expertise, AI literacy, project management) those who can build reliable loops around their own work may protect more time for actual scientific depth.
The deeper point is that domain expertise becomes more valuable, not less. A language model can reorganize notes. It cannot decide which scientific path is worth taking.
Open Question
I do not think the most important question is whether these systems will become more capable because I know that they are increasingly so and every day. The harder question is what a trustworthy and open personal research operating system should look like in science.
How much should remain personal (hidden and protected) and adaptive to one person’s way of thinking? How much should become standardized (sterile?) for transparency, reproducibility, and collaboration? Will streamlining reduce the diversity of research operation?
A second question is the computing cost of running these systems: API won’t be free for too long, how much are we willing to pay for research productivity tools and will research sponsor agree to pay these fees? How can we, AI amateurs, keep experimenting to reduce cost while keep up with the pace of technical innovation and advancing our research? Are these costs truly improving our research productivity as measured by dissemination of our knowledge through publication and open science artifacts?
Maleen’s workflow does not answer these questions yet. But the real significance of experiments like this one demonstrates that early prototypes of how scientific work itself may be reorganized.
Notes from Maleen
“I stopped trying to remember where I left off. The vault remembers, and I get to spend that hour actually thinking about the science instead of reconstructing last week.” - Maleen Kidiwela
VaultNotes is open source and publicly available at github.com/MaleenKidiwela/vaultnotes; anyone with an Obsidian vault can install it with a single command and run their own copy. Gemini is used for embeddings of the notes, Claude for the rest. Check out what the dashboard looks like here.
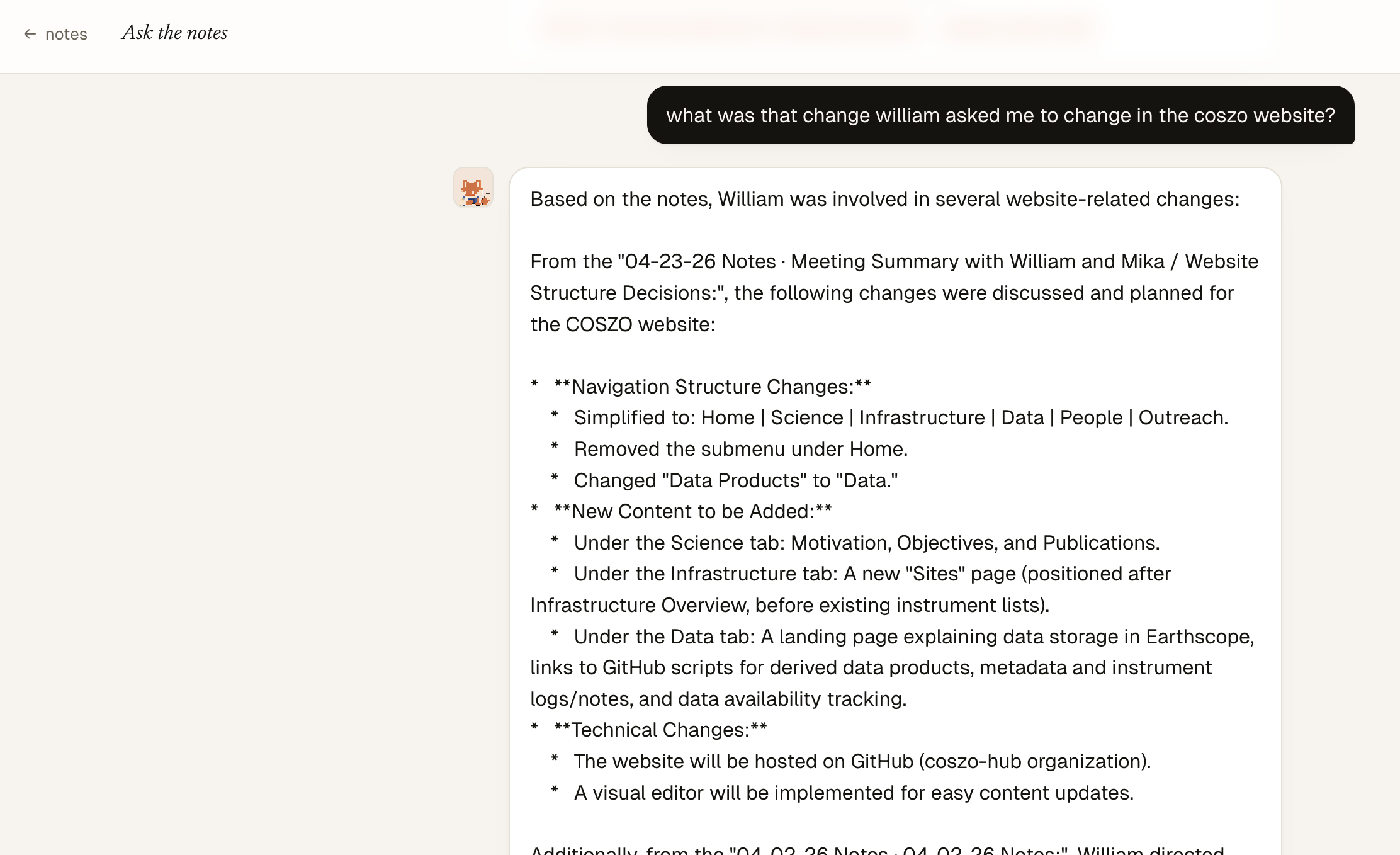 Screenshot of the VaultNotes “Ask the notes” chat panel answering a question grounded in the published vault.
Screenshot of the VaultNotes “Ask the notes” chat panel answering a question grounded in the published vault.
Optional Short Bio Box
Maleen Kidiwela is a postdoctoral researcher at the Cascadia offshore subduction zone observatory, working on data quality assessment, database design, data streams, and intelligence layers for large multimodal observatory databases. He builds VaultNotes on the side as an experiment in what a personal research operating system looks like when retrieval, planning, and lightweight automation are designed around an actual scientific workflow rather than a generic productivity one.