Why This Blog Exists
The Slide That Started This
I was preparing a seminar — a vision talk that needed to weave together two subfields I have spent my career spanning: environmental seismology and earthquake seismology. These are domains that share the same physics (hydromechanics and seismic wave propagation) but operate at different timescales, different spatial scales, and different institutional traditions. Unifying them in a single coherent narrative is something I have been working toward for years.
I did not ask ChatGPT to build the seminar from scratch. I had already uploaded a substantial body of my own writing — papers, proposals, research statements — into my OpenAI business account over the past nine to twelve months. For those worried about “leaking data to corporation”, the platform does not train on my data with my account, and even if I did share my own knowledge for training, I’d be happy that it would train on my work as a scientist supported by tax-payer and students money. Over that period, through hundreds of interactions across multiple structured projects, the model had accumulated a working understanding of how I think about Earth systems, sensing, hazards, and the physics that connects them.
So I asked it to help me organize the arc of the seminar. And as part of that conversation, it proposed a slide concept that contrasted environmental seismology and earthquake seismology around a shared hydromechanical core — without me specifying which aspects should be compared.
I prompted: generate an image of this slide.
What came back was this:
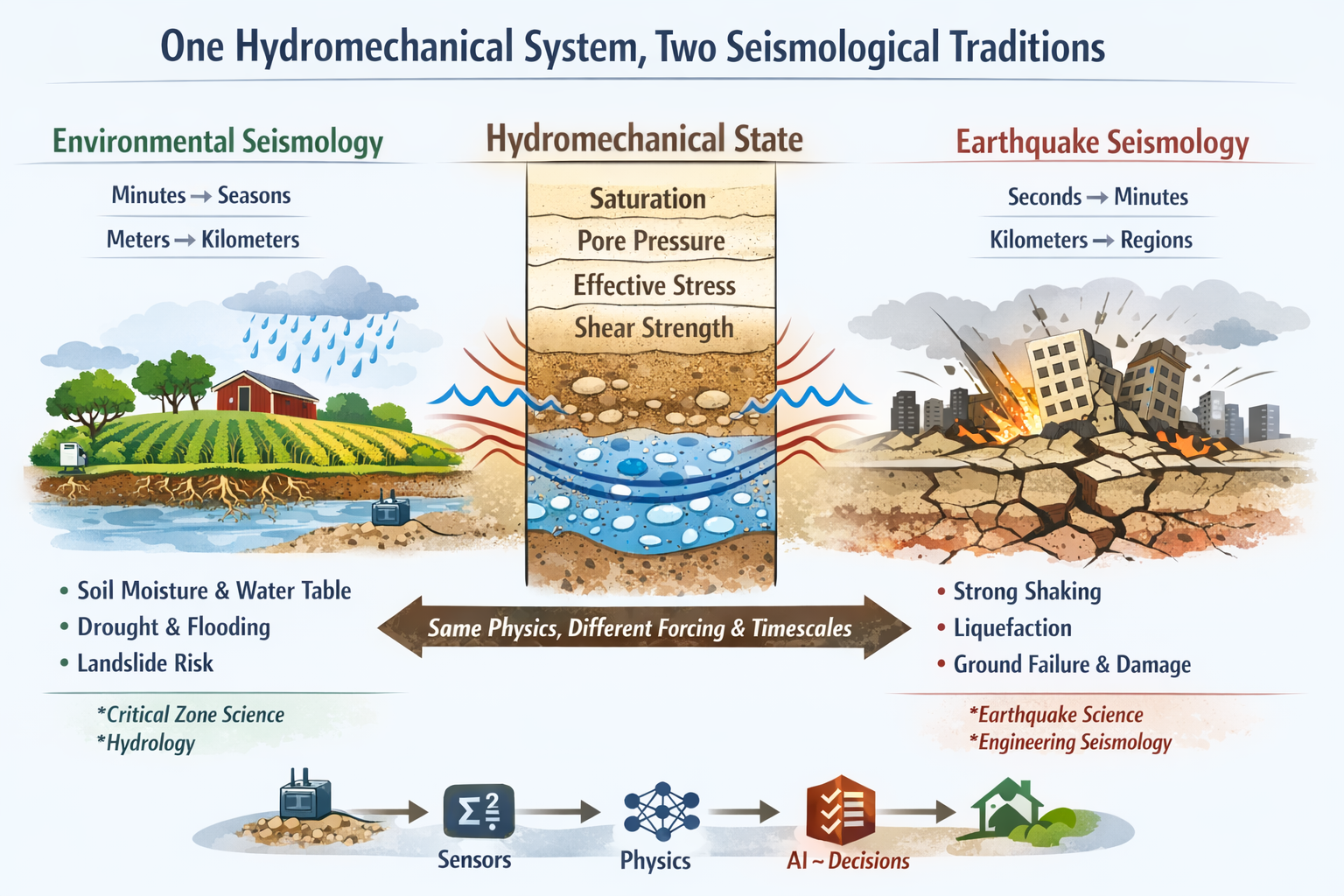
The slide captures the contrast with a precision I did not expect. Environmental seismology on the left: minutes to seasons, meters to kilometers, soil moisture, drought, landslides — grounded in critical zone science and hydrology. Earthquake seismology on the right: seconds to minutes, kilometers to regions, strong shaking, liquefaction, ground failure — grounded in earthquake science and engineering. At the center, the shared hydromechanical state: saturation, pore pressure, effective stress, shear strength. And at the bottom, the pipeline I have been building toward: sensors → physics → AI → decisions, with a minor typo on the bottom.
One prompt. One image. A synthesis that would have taken me hours to diagram manually, produced in seconds — and produced correctly.
This was a moment for me.
What Changed
I have been using generative AI seriously for about a year. For most of that time, I would have described these tools as B-minus instruments — useful for drafting, adequate for brainstorming, but requiring substantial iteration before the output was trustworthy. Especially for anything visual or structural, I expected to prompt, correct, re-prompt, correct again, and eventually settle for something close enough.
Something recently changed to me. Models are improving faster than my calibration of them. The hydromechanical slide was not the product of a long prompting session. It was a single generation from a model that had absorbed enough of my context — through months of uploaded documents and structured interactions — to synthesize across two subfields I care about deeply.
GenAI is advancing faster than the rate of advancement in science itself. The tools I dismissed as requiring heavy supervision six months ago now produce output I would present to colleagues without hesitation. That rate of change is what prompted me to write publicly about this.
The Role I Am Playing
I am an associate professor at the University of Washington. I build data-driven models of Earth systems, stemming from seismology and geophysics. I am drawn to problems where computational scale and physical reasoning intersect — environmental seismology, earthquake hazard characterization, sensing infrastructure, and increasingly, AI-augmented scientific workflows.
I am not writing this blog as an AI commentator. I am not theorizing about what foundation models might do for science. I am describing what they are already doing in my own practice, right now, across the multiple roles that define my academic life:
- Curriculum builder — translating textbooks into living course materials using AI synthesis
- Proposal architect — structuring large interdisciplinary funding narratives with AI-assisted framing
- Researcher — prototyping data pipelines, analysis workflows in VS Code with Claude (mostly)
- Reviewer — auditing my own manuscripts and those I referee with structured AI review
- Mentor — iterating on feedback and advising strategies before deploying them with students
- Communicator — preparing seminars, vision talks, and public-facing materials
- Academic Service — preparing university/department committee summary, slideck, syllabi templates, meta-analysis of educational programs.
Each of these roles interacts with GenAI differently. Each requires different prompting strategies, different context, different guardrails. The blog will examine them one at a time.
How It Works, Practically
My setup is deliberate but not complicated.
I use a business OpenAI account with persistent “Projects” — each one structured around a major academic role. A seismology course project has the syllabus, textbook sections, and learning objectives attached. A proposal project has the solicitation, budget constraints, and prior reviewer feedback. Each project carries standing instructions that I have iteratively refined — initially drafted informally, then asked the model to formalize into structured task specifications closer to agent design than casual prompting.
For coding and software development, I work in VS Code with Anthropic’s Claude (Sonnet and Opus), switching from Codex after noticing a dramatic difference between the two a month ago, and alongside GitHub Copilot. The annual cost across all platforms is under $1,000 — less than a single publication charge.
The key mechanism is context layering. The model does not start cold. It works within a structured environment where my domain knowledge, constraints, and objectives are pre-loaded. When I asked it to organize that seminar arc, it was not reasoning from general knowledge about seismology. It was drawing on my framing of these subfields, from documents I had written and uploaded over months. The slide was accurate because the context was accurate.
This is not magic. It is careful, cumulative context engineering.
Where It Fails
I do not want to overstate this.
Foundation models hallucinate. They produce confident, cleanly formatted output that is subtly wrong. In my seismology course development, I have caught errors in focal mechanism polarities, sign convention inconsistencies in moment tensor decompositions, and in the past , misattributed references. Each error was embedded in otherwise excellent output — the kind of mistake that a student or non-expert would not catch.
The models also guess when they do not have the knowledge in training or in context (hallucination). They do not flag uncertainty in domain-specific physics. They do not say, “I am unsure whether this P-wave polarity pattern is correct for a thrust mechanism.” They present it. You verify it or you accept it uncritically. Maybe this will change in the future.
This is why domain expertise has become more important in my workflow, not less. The AI accelerates production, and I correct it when needed. Every post in this series will include a section on where the AI failed or where I overrode it.
The Pattern I Am Observing
Here is the claim I am making:
GenAI re-weights cognitive labor in academia. It does not replace expertise. It shifts where expertise is applied — from production to verification, from drafting to judgment, from building to curating.
When peripheral tasks (formatting, initial synthesis, visual prototyping, document structure) become faster and more competent, cognitive bandwidth returns. That bandwidth can be reinvested into the parts of science that remain irreducibly human: asking the right question, reading the room in a mentoring conversation, catching the polarity error in a focal mechanism diagram.
This blog describes what genAI is transforming in my practice, as I test it in real time.
What I Have Not Resolved
The seminar slide worked because the model had absorbed my context over months. It was accurate because my inputs were accurate.
But what happens when the context itself is uncertain — when I am exploring a subfield where I lack strong priors? Many scientists raise this concern rightly: confident fluency can mask poor knowledge of vetted science.
I take that seriously. But I believe the answer is better engineering, not avoidance. You can instruct models to test for prior knowledge, flag uncertainty, and distinguish established results from speculation. You can build evaluation loops with verification. I have been recently doing this: long, structured instructions closer to agent specifications than casual prompts. No amount of instruction design fully substitutes for domain knowledge, but strong guardrails work.
This blog is my attempt to navigate that experimentation in public — to document what works, what fails, and what I am still figuring out. These are reflective field notes from active experimentation, not tutorials. They are open to discussion through GitHub Discussions, where you can comment, suggest improvements, add your own skill files.
I do not believe every scientist must integrate AI deeply. But I do believe that domain experts should be the ones shaping how it enters scientific practice. This is my contribution to that shaping.